En los tiempos en que se diseñaban estos computadores se hacían prototipos físicos, no habían computadores para simular el comportamiento ni nada de eso. Simplemente se armaban protobards, se conectaban todos los cables y sobre eso se iteraba, era natural que sólo el diseño se planificaba para ser realizado en varios meses o incluso años.
Hoy en día no existe ese problema y los computadores son tan potentes que pueden perfectamente ayudar a diseñar y simular nuevos chips, así como existen emuladores para simular chips antiguos por qué no crear un emulador también para simular un chip que no existe? Eso permite experimentar y refinar el diseño antes de convertirlo en hardware real y elimina la limitación de ajustarse al hardware existente. Si a esto agregamos que existe tecnología como FPGA que permite implementar diseños electrónicos de nuevo hardware via hardware existente, el camino de un diseño en software a una ejecución en hardware es posible.
Afortunadamente hay suficiente información de cómo diseñar chips de video, tenemos el mismo código de los emuladores, y en camino viene un libro que trata sobre el diseño del ULA en el Spectrum. También Leonardo Ruilova me recomendó otro libro de la misma temática, escrito por uno de los creadores de un proyecto similar, XGameStation.
Alternativas
Hay múltiples alternativas para resolver el problema del chip de video. Siempre pensando en que es un proyecto de largo plazo y hay tiempo para experimentar, veo las siguientes opciones:
Que este nuevo hardware simplemente corra sobre hardware potente como una Raspberry Pi, como si fuera un emulador de toda la vida, pero a diferencia de los emuladores existentes, éste siempre sería perfecto, pues no existe el hardware a emular y la única referencia sería el código del emulador. En este caso el chip de video sería un emulador de un nuevo chip, implementado en la Raspberry Pi. Posteriormente se podría crear el hardware real y quizás sería un raro caso en donde primero se construye el emulador y luego el hardware.
Utilizar VGA pero con un procesador dedicado sólo a video. VGA sólo actuaría como framebuffer, y el procesador dedicado sería el equivalente a un custom chip del Amiga o a un chip de aceleración. Este chip tendría acceso casi exclusivo a la VRAM y operaría a una frecuencia diferente del procesador principal. El chip estaría inicialmente implementado en software controlando la VGA física. Si consideramos que un PC antiguo puede emular perfectamente computadores de 8-bit y 16 bit, la dedicación exclusiva a procesar video es perfectamente posible.
Utilizar un chip de video existente. En el proyecto de 8-bit guy están siguiendo este camino, pero está el inconveniente de que aparecen las restricciones del chip de video existente. Por ejemplo el chip que están usando sólo puede generar graficos tiled (como una NES), y la interfaz de comunicación es serial. Por ahora esta alternativa está descartada (*)
Utilizar un chip de propósito general para generar video. Es algo similar a la opción de usar VGA sólo que el chip generaría directamente la señal de video. Es una opción bastante interesante y ya se ha hecho, pero por problemas de rendimiento no se pueden generar muchos colores con los chips conocidos.
(*) Sigo atentamente la evolución del proyecto de 8-bit guy y está bastante activo. Hoy publicaron un demo de lo que pueden hacer con Gameduino y es bastante impresionante, pero nuevamente se aleja de la esencia del proyecto que es tener limitaciones de recursos de la época.
Por ahora, creo que el camino más flexible es implementar un emulador de un chip que genere un framebuffer. Esto permitiría tener un diseño en el corto plazo y ya con más experiencia poder tomar cualquiera de estos tres caminos: Mantener la emulación, Controlar una VGA, Utilizar un chip de propósito general.
Actualización: Hay un proyecto similar llamado Anvil-6502 en donde hicieron un chip de video que funciona bastante bien. Es principalmente bitmapped y requiere un procesador rápido, pero puede servir de base para convertir el framebuffer en señal de video. Hay unos demos bastante espectaculares.
Hace un tiempo atrás 8-bit guy presentó una idea maravillosa, y es diseñar un computador antiguo pero usando tecnología moderna. Es justamente un tema al que le había estado dando vueltas hace tiempo – desde que me puse a programar Prince of Persia para Atari probablemente – y cuando comencé a ver el video sobre este nuevo computador fue como «esto es!». Lamentablemente mientras avanzaba el video vi que tomó rápidamente otra dirección y al revisar el grupo de Facebook en donde se discute el diseño vi que el proyecto se anduvo desvirtuando un poco. Asi que, con los recursos que contamos hoy en día me dije, entonces por qué no crear algo yo mismo?
Vamos un poco más atrás, por qué uno se interesaría en diseñar un computador antiguo? Quién lo va a usar? Para qué se usaría? Parte de las respuestas están en el mismo video, al menos para mi la gracia de un computador antiguo es que sus recursos son escasos, y esa limitación hace que uno comience a pensar en soluciones creativas, es un poco lo que se ha hecho con proyectos como PICO-8. En la actualidad es prácticamente posible hacer lo que a uno se le ocurra en el computador, al no haber límites como que programar en ellos pierde un poquito la gracia, y si bien esto es muy conveniente para hacer software que resuelve problemas complejos y «serios», al mismo tiempo para mi se convierte en algo bastante aburrido. Si, soy cuático, lo sé…
Otro motivo es que los computadores antiguos existentes tienen componentes propietarios que van camino a desaparecer, con el tiempo serán cada vez más escasos y costosos. Por ejemplo chips como el PLA o los VIC de Commodore ya no se fabrican, y aunque existen versiones modernas (del PLA), no se está exento de dificultades a la hora de la compatibilidad.
Ya pero quién lo va a usar?
Sobre la pregunta de quién lo va a usar, la respuesta es muy simple: Yo. Si algún otro loquito se entusiasma, pues muy bien! Pero esto es algo personal primero, si aun me quedan unos 30-40 años de vida hay tiempo suficiente para entretenerme con un proyecto como éste.
A diferencia del proyecto de 8-bit guy éste no es necesariamente un computador para vender. Incluso en sus inicios no necesita existir físicamente, con la tecnología de emulación existente (algo cacho) se pueden integrar los componentes a gusto y trabajar con eso. Si el proyecto agarra vuelo quizás alguien se interese en crear una placa y hacer que el sistema exista físicamente. Sería interesante por ejemplo poder alojar este nuevo computador en carcasas ya existentes y que tienen diseños que me encantan, como la del el C64C o la linea Atari XE, incluso hasta existen carcasas nuevas que son toda una delicia.
Criterios de diseño
Primero, este proyecto no se trataría de un solo computador, sino de una linea de computadores. Hay diferencias de hardware suficientes para distinguir al menos dos generaciones de computadores interesantes: 8 bit y 16 bit. En la generación de 8 bits pensemos en lo que ya existe: Atari 800, C64, ZX Spectrum, MSX y Amstrad básicamente. En 16 bits tenemos principalmente Atari ST y Commodore Amiga. Un nuevo computador para cada generación debería ser similar en tecnología pero con algunos pequeños cambios necesarios. Primero, no se podrían utilizar componentes ultra propietarios como los chips de video (ULA, ANTIC, GTIA, VIC, etc). Segundo, no se podrían utilizar componentes ultra modernos porque violaría el principio inicial de este proyecto, por ejemplo un chip de video como el de la raspberry Pi estaría completamente descartado, en ese caso mejor programamos para Linux con SDL/OpenGL y ya.
Otro criterio importante es la disponibilidad de componentes. Al menos la CPU, el audio y componentes como memoria y otros de más bajo nivel pueden ser «off the shelf». En cuanto a video el tema se vuelve un poco más complicado porque a excepción de hardware como VGA, no hay componentes off the shelf que se puedan usar directamente manteniendo los criterios del párrafo anterior.
Otro criterio es el software al que va orientado. No se necesitan computadores para correr herramientas productivas, para eso tenemos los computadores modernos, por lo tanto modos de texto de 80 columnas o modos de video de alta resolución pero de dos colores no tienen mayor sentido. Sólo se necesita lo justo para correr juegos que se vean bien en sistemas de televisión análogos usando aspecto 4:3.
Finalmente, otro criterio es el factor WOW. Pensemos en que estamos en 1988 y un nuevo computador de 8 bits es anunciado, qué anuncio nos sorprendería y nos haría ahorrar cada día para poder comprar ese computador? Un efecto similar a cuando veíamos los anuncios de revistas como MicroHobby en donde aparecían unas capturas de pantalla fabulosas, aunque al final los juegos reales no eran «tan así». Recuerdo cuando fue anunciado el 130XE, lo primero que uno pensaba era en las capacidades de color y sonido mejoradas, pero al final solamente era más memoria, que casi ningún juego aprovechaba. También está el caso del ST que encabeza este artículo, que en capturas se veía muy bien, pero en la realidad la paleta de colores era mucho más básica de lo que se veía en las capturas, no tenía scroll por hardware y en general era bastante precario comparado con el Amiga.
La definición que viene a continuación es sólo la idea original, pensemos en que sólo lo estoy anotando acá para que en el futuro no se me olvide, pero sirve para dar una linea a seguir o plantear alternativas sobre las cuales discutir si alguien se interesa. Tómenlo como un brainstorming, quizás son combinaciones imposibles o que rompen los criterios ya mencionados, pero el tiempo dirá.
Hardware de 8 bits
Procesador: MOS 6502 y Zilog Z80, Dual Boot como el C128
Modo texto: 40×24, 16 colores, caracteres redefinibles
32 sprites de 16 colores (con 1 transparencia)
Video Ram: 128K
Interrupción por linea
Interrupción vertical
Scrolling por hardware
(vaya creo que se parece al chip del MSX2)
2 puertos de Joystick
Joysticks de 2 botones
Controles análogos (mouse, paddle)
Sistema de almacenamiento via tarjetas SD
SDK: BASIC y Assembler
Hay que considerar que el hardware de video está limitado por la velocidad del sistema completo, un procesador como los indicados no es capaz de manejar rápidamente grandes cantidades de memoria, por lo que una alta resolución con muchos colores se topa con el problema de que el procesador necesita varios frames de la pantalla para poder manipular todos los bytes que representan un único frame, por lo que o bajas los frames por segundo o aparece el famoso tearing. Por eso se agrega el modo tiled, un buen modo de texto y display lists, ellos permiten combinar distintos modos de video en una sola pantalla y hacer que el chip de video haga lo mejor que pueda con usando menos memoria.
Por otra parte la similitud del hardware con el existente de esa generación permitiría hacer ports de juegos existentes pero con las mejoras que permitiría este nuevo hardware. Imaginen por ejemplo remakes de juegos originales de 8 bit como Draconus, Montezuma pero usando más colores y mejores opciones de sonido, ya no se tendrían que hacer sacrificios del tipo «música o efectos de sonido». O sin ir muy lejos, ver lo que ya se ha hecho con los isométricos clásicos de ZX Spectrum en MSX2.
Hardware de 16 bit
Procesador Motorola 68040 a 40Mhz
Audio: Stereo OPL3 + 2 Canales DAC por lado. Con esto se tiene lo mejor de ambos mundos, se pueden usar samples y sintetizadores sin que sea necesario emular sintes con samples y viceversa.
Memoria: 4MB
Video:
Salida de video compuesto y por componentes
320×240 pixels
256 colores de una paleta de 262.144 colores
Display lists
Modo bitmap
Modo texto: 40×24, 16 colores, caracteres redefinibles
Blitter para BitBlt y Fill (sin sprites)
Escalado y Rotación
Video Ram: 512K
Interrupción por linea
Interrupción vertical
Scrolling por hardware
2 puertos de Joystick
Joysticks de 2 botones
Controles análogos (mouse, paddle)
Sistema de almacenamiento via tarjetas SD
SDK: C y Assembler
Por supuesto que si bien hay dos generaciones planteadas, no significa que se trabajaría en ambas al mismo tiempo, es conveniente partir de una arquitectura pequeña como la es la de 8 bit y una vez ganada la experiencia – y si quedan ganas – seguir con la generación siguiente… Total, aun quedan 30-40 años para hacerlo.
Ideas locas
Componentes como los procesadores tienen restricciones físicas, principalmente su frecuencia de reloj, aun así se ha logrado crear hardware con estos procesadores overclockeados, por lo que se puede asumir que esto siempre es una posibilidad. Por ejemplo el 6502 normalmente corre bajo 2Mhz, pero perfectamente se puede pensar en que corra a 10Mhz. Lo mismo con el Motorola 68XXX, hay tarjetas de aceleración para el Amiga en donde se obtienen frecuencias mayores que ayudan sobre todo a los juegos que requieren muchos cálculos, como los poligonales.
A continuación dejo algunos videos a modo de inspiración, en donde se puede ver lo que hoy se hace con computadores de 8 bit que ya están bastante limitados, aun así los programadores han logrado hacer cosas que sus diseñadores originales jamás pensaron.
Después de mucho postergarlo, finalmente decidí dejar Mac OSX y volver a Linux. Son varios los motivos y puedo decir tranquilamente que OSX no es para nada un mal sistema, de hecho para un usuario como yo es una excelente combinación de la potencia y flexibilidad de Unix con la disponibilidad de aplicaciones mainstream nativas en el sistema.
Pero yo quería otra cosa.
Ubuntu GNOME y Eclipse
Con Linux me había acostumbrado a poder modificar lo que yo quisiera del sistema. Usándolo todos los días tiendo a aburrirme y en OSX como mucho podía cambiar el fondo de pantalla y el color de la barra superior, del resto prácticamente nada.
Por otro lado, para el tipo de uso que le doy al computador las herramientas en Linux están mucho más a la mano, en OSX están a través de brew o macports pero siempre son ciudadanos de segunda clase. Ni hablar de tratar de compilar PHP para que use SQL Server, Oracle y cosas por el estilo. Incluso algo tan simple en Linux como poder escribir unidades NTFS puede volverse un infierno en OSX.
En fin, al momento en que quise cambiar el look & feel de OSX para que fuera obscuro y así descansar más la vista y no pude, y al mismo tiempo el anuncio de Canonical de abandonar Unity fue el empujón que necesitaba para dar el paso. Ah! Y ya que estaba desconectado del desarrollo de GNOME por mucho tiempo, este review de Ubuntu GNOME me entusiasmó mucho más.
Y aquí estoy, escribiendo desde Ubuntu GNOME en mi computador principal. Primero hice unas pruebas en mi portátil, cuya configuración la puedo armar en cualquier momento desde cero. Lo usé unos días y me convenció completamente, todo el hardware fue soportado sin hacer nada especial, incluso unos audífonos bluetooth que no funcionan en OSX sí funcionaron en Linux. Para qué decir del software, fue como sentirme de vuelta en casa con el añadido de que GNOME es quizás el mejor sistema de escritorio que he usado. Ojo, antes que los Apple fan se me tiren encima, si no lo han probado no tienen como opinar. Sólo al usarlo te das cuenta de que en GNOME han hecho un excelente trabajo.
Advertencia
Antes de que me digan «ah no, es que yo uso la aplicación X» vamos a ser claros, cada uno usa el sistema que más le acomode y eso depende mucho de las aplicaciones que uno necesite para su trabajo diario. En mi caso tanto OSX como Linux me sirven, por lo que la elección de uno u otro sistema corresponde a otros factores, como los descritos arriba.
Para entender el caso, esto es lo que uso frecuentemente: Java SDK, Android SDK, Android NDK, Eclipse, GNU tools (build tools, bash, etc), MySQL PHP, un navegador, Dropbox, GIMP. En menor medida: Utilidad para analizar el uso del disco, monitores de sistema (temperatura, uso de recursos), etc. Como pueden ver, todas estas herramientas están disponibles en ambos sistemas operativos, nativamente en Linux y a través de diversos mecanismos en OSX.
Seguramente hay algunos que quieran hacer la prueba o solucionar algún problema o duda respecto a instalar Linux en hardware de Apple, así que en el resto del artículo dejaré documentado lo que he ido ajustando en el sistema.
Instalación
Para no llenar de imágenes este post, a través de links dejaré screenshots de referencia. La instalación inicial se resume en los siguientes pasos:
Dejar espacio libre en uno de los discos. En OSX con Utilidades -> Utilidad de disco pueden reducir el tamaño de la partición actual para dejar un espacio libre a Linux
Una vez instalado el sistema, se reiniciará el equipo y partirá con Linux. Si quieren partir con OSX, usen nuevamente la combinación CMD+X a menos que les aparezca el menú de rEFInd. (A mi a veces me ha aparecido, a veces no).
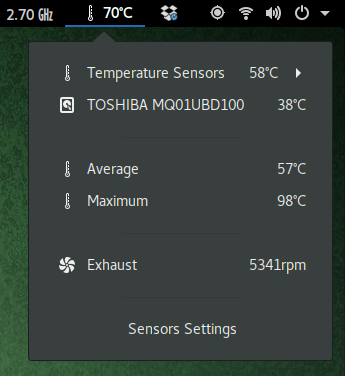
Temperatura, ventiladores y uso de CPU
Con un sistema recién instalado lo primero que notarán es que el equipo se calienta. Eso es porque falta instalar una utilidad que controle el ventilador. Como preferencia personal a mi me gusta ver el uso de CPU y temperatura en el panel, así que vamos a instalar todo de una. En un terminal:
lm-sensors: permite obtener información de temperatura y velocidad de rotación de los ventiladores
cpufrequtils: permite ajustar la forma en que la CPU cambia de velocidad. La idea es que sólo use una alta velocidad sólo cuando sea necesario
macfanctld: con la información de temperatura, esta utilidad controla automáticamente la potencia de los ventiladores. Si la temperatura sube, aumenta la potencia de los ventiladores, y al bajar, reduce la potencia.
tlp: Se encarga de aplicar ajustes para reducir el uso de batería en portátiles
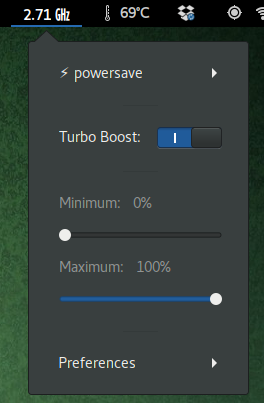
No se preocupen que en ningún caso usarán estas herramientas directamente, a menos que quieran modificar su comportamiento. Lo normal es que instalen alguna aplicación de escritorio que usará estas herramientas para controlar el sistema. En mi caso instalé extensiones de GNOME shell que entregan información de uso en la barra superior y permiten realizar ajustes del sistema en forma gráfica. Mis elegidas fueron:
Al instalar estas aplicaciones pude entender un problema que siempre tuve con OSX en mi MacMini, y es que el equipo se calienta demasiado, al punto en que la tarjeta WiFi comenzaba a fallar. El MacMini en general es MUY silencioso a menos que esté trabajando en forma intensiva, y esto es simplemente porque el ventilador no comienza a funcionar sino hasta que la temperatura es muy alta. Por lo tanto, en general el equipo andaba con alta temperatura pero en silencio. Al instalar macfanctld lo primero que llama la atención es que el ventilador parece estar andando siempre, pero es simplemente porque la configuración de origen está hecha para mantener el sistema andando a temperaturas razonables, y para eso tiene que usar constantemente el ventilador.
Por lo tanto queda la opción de a) alta temperatura y silencio o b) baja temperatura y ventilador andando. Como ahora estamos hablando de Linux, basta modificar el archivo de configuración de macfanctld para ajustarlo como uno quiera. Se puede definir la velocidad de rotación mínima y dos temperaturas: La temperatura mínima en donde el ventilador estará en su potencia mínima definida, y la temperatura máxima en donde el ventilador funcionará a toda su potencia.
Freon GNOME Extension
Sin tener datos exactos, pero recordando cómo funcionaba esto en OSX podría estimar los valores que estaba usando en mi equipo. Si quisiera resumir todos los valores tenemos:
OSX en MacMini: 1500RPM, min 80º, max 90º (estimado)
Ajustes originales de macfanctld: 2000RPM, min 45º, max 55º (macfanctld.conf)
Mis ajustes de macfanctld: 1800RPM, min 60º, max 70º (personalizado)
Config actual un poco más tibia pero más silenciosa: 1800 RPM, avg 70º – 80º, periferia 50º – 68º
Ahora el ventilador se mantiene más activo, pero ya no me quemo al tocar el macmini.
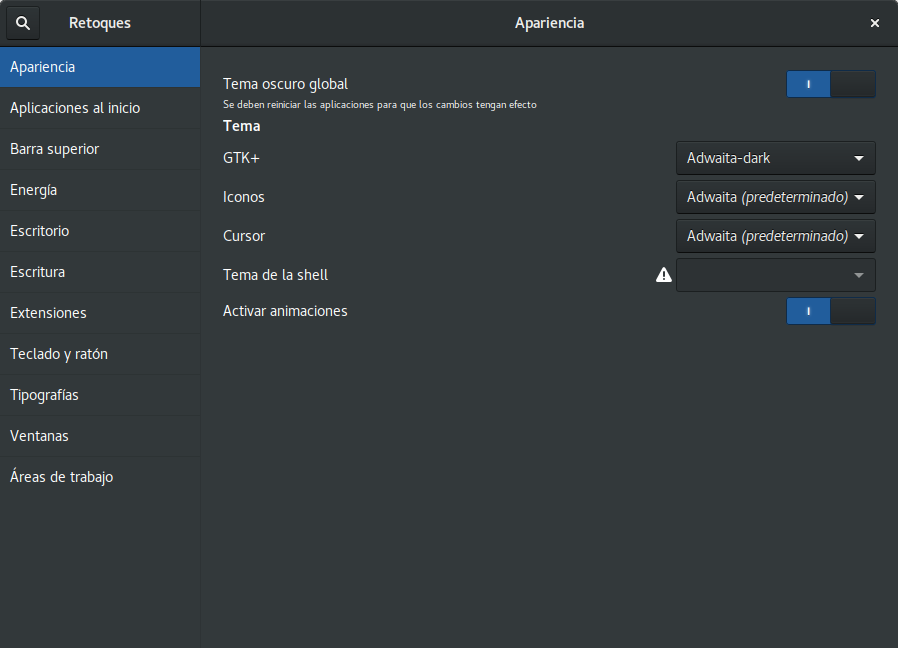
Lo que gatilló el cambio con fuerza fue contar con un escritorio obscuro para descansar la vista, y Ubuntu GNOME viene preparado para hacer ese cambio de una forma muy sencilla. Simplemente deben abrir la Herramienta de retoques de GNOME Shell y en Apariencia activar Tema obscuro global y luego en Tema -> GTK+ poner Adwaita-dark.
GNOME Dark settings
Java y Eclipse
Si bien Ubuntu incluye Eclipse, es una versión relativamente antigua. Personalmente prefiero instalar la última versión de Eclipse desde el sitio oficial e instalar JDK 8 de Oracle.
Para instalar Elipse, descargan el instalador, lo descomprimen y ejecutan. Presentará varias opciones de instalación, yo seleccioné Eclipse for Java Developers.
Ajustes adicionales de Eclipse
Eclipse a secas no tiene todo lo que suelo ocupar, asi que en Ayuda -> Eclipse Marketplace siempre instalo las mismas extensiones a las que ahora se agregan aquellas para obtener un aspecto obscuro. Una funcionalidad no muy conocida del Marketplace es que pueden marcar extensiones como favoritas, para que sea más fácil instalarlas en un Eclipse nuevo, simplemente abren los favoritos y ponen «Instalar todo».
Mis extensiones favoritas de Eclipse son:
Eclipse C/C++ IDE (CDT)
PHP Development Tools (PDT)
Android Development Tools (ADT)
Subclipse
Eclipse Mooonrise UI Theme
Eclipse Color Theme
Eclipse Data Tools Platform (DTP)
Las últimas dos ayudan a darle el aspecto obscuro. Una vez instaladas van a Preferencias -> Apariencia -> Tema y seleccionan Moonrise Standalone. Luego en Preferencias -> Apariencia -> Colores seleccionan el que sea de su agrado. Yo estoy usando Gedit Original Oblivion.
Eclipse en Ubuntu GNOME
Música
Para no duplicar mi biblioteca de música, importé los archivos directamente desde mi antigua librería de iTunes. Inicialmente podía ver la partición de OSX en Archivos -> Otras ubicaciones, pero la carpeta /Users/fcatrin/Music no tenía permisos de lectura. Para solucionarlo inicié en modo rescate de OSX (CMD+R), entré a mi carpeta personal via terminal y apliqué:
chmod 755 Music
Luego reinicié y agregué la carpeta en Rhythmbox
Biblioteca iTunes en Rhythmbox
De origen no viene incluido un ecualizador, pero hay uno disponible a través de plugins. Acá pueden encontrar ese y otros bastante interesantes: Installing rhythmbox 3.0 plugins … the easy way!
Android
Para Android un par de problemas al intentar levantar un emulador:
Primero no me dejaba crear una máquina virtual (AVD), fallaba al crear la tarjeta SD. Eso fue porque la utilidad que crea la tarjeta SD es de 32 bits y requiere bibliotecas de 32 bit que no son instaladas como parte del SDK. La solución es sencilla:
sudo apt-get install lib32stdc++6
El segundo problema fue la aceleración de video que no queda lista para llegar y usar. Se requiere instalar glxinfo y actualizar una biblioteca del SDK copiando la que ya tienen en el sistema. Se reduce a:
Con eso quedará instalado glxinfo, y actualizada libstdc++ apuntando a la que está instalada en tu sistema.
Otros ajustes
Hay otros ajustes que se pueden hacer al sistema para que quede más sintonizado con los sitios web existentes, el idioma local, entre otros. En esta lista están:
Instalar los paquetes de corrección ortográfica al español
Para Dropbox pueden ir al instalador de aplicaciones Software que se encuentra en los iconos de la derecha y buscar por Dropbox. El sistema descargará e instalará Dropbox automáticamente.
Dropbox muestra un ícono de actividad en la barra de notificaciones que no existe como tal en GNOME, pero para variar, hay una extensión que la habilita, se llama TopIcons Plus.
En cuanto a los idiomas, usualmente escribo en inglés y en español indistintamente, lamentablemente Firefox sólo permite usar un idioma a la vez. Hay una forma de unir los archivos de corrección ortográfica como un solo idioma pero no lo he hecho aún.
Al usar un tema obscuro en Firefox se puede tener problemas con los campos de texto, ya que a veces los sitios modifican sólo el color defondo o sólo el color del texto y quedan invisibles porque asumen que el fondo es blanco. Acá hay varias opciones para solucionar el problema de campos de texto en theme obscuro, personalmente me quedé con agregar un archivo userContent.css.
Creo que eso es todo por ahora, seguramente iré agregando más detalles en este post. Espero quedarme con Linux por un buen tiempo.
Finalmente: Tal como lo recordaba, los fonts en Linux se ven mucho más suaves y definidos que en OSX.




{kind=link}
{kind=link}
{kind=link}
{kind=link}